1. Enterprise AI Platform
TensorOpera is the next-gen cloud service for LLMs and Generative AI. It helps developers or AI/ML teams to launch complex model training, deployment, and federated learning anywhere on decentralized GPUs, multi-clouds, edge servers, and smartphones easily, economically, and securely.
You can buy our advanced plan or enterprise service for your specific needs in on-premise deployment and dedicated support in any aspect of the entire ML pipeline. More details are as follows:
Features Overview
2. Model Serving
2.1 Serverless Endpoints for Open Source Model
Pay-as-you-go for popular open-source LLM and generative AI models. Rapid API integration in minutes without any GPU server setup. Easy upgrade to dedicated endpoints with MLOps support.
* The prices listed are for 1 million tokens, which includes both the input and output tokens for chat, voice, and code models. For embedding models, the price is based only on the input tokens. Furthermore, the price is determined by the number of steps for image/video models and the number of output seconds for audio models. For multi-modal models like LLaVA, each image is counted as the equivalent of 576 prompt tokens for billing purposes.
2.2 Dedicated Endpoints for Your Own Model
You can host your own model on TensorOpera Secure Cloud with the TensorOpera Platform, which supports autoscaling across clouds, manual scaling, model versioning updates, logging, and system monitoring. We support both docker images and custom Python APIs for easy integration.
Enterprise service: If you need help with complex custom deployment (multiple models, cross-server workflow, distributed serving in multiple clouds, etc.) or throughput/latency optimization, don't hesitate to contact us .
3. AI Agent API
AI Agent API is similar to OpenAI Assistants API but can be customized with your own LLM or vector database. You can try it on the TensorOpera Platform (click the left-side "AI Agent" tab). The LLM-based AI Agent can utilize LLMs, tools, and knowledge to respond to user queries. The LLM Agent uses LLM as its “brain”, learns to call external APIs (tools) for additional information that is missing from the model weights, and also leverages the vector database-backed RAG (retrieval augmented generation) as its "memory".
The LLM tokens used for the LLM are billed at the chosen endpoint. It can be either dedicated endpoints or serverless endpoints. The additional cost is as follows:
| Tool | Input |
|---|---|
| Code Interpreter | $0.03 / session |
| Retrieval | $0.20 / GB / agent / day |
Enterprise service: If you are not satisfied with the performance of your LLM Agent, we can provide you with guidance in LLM fine-tuning, RAG optimization, and prompt engineering ( contact us ).
4. Serverless Training, Fine-tuning, or Federated Learning
TensorOpera Platform supports serverless AI jobs with TensorOpera®Launch. You only need to pay per use for your job. We provide many free pre-built job templates (training, fine-tuning, or federated learning) in Studio or Job Stores on the TensorOpera platform.
TensorOpera Launch can swiftly pair AI jobs with economical GPU resources to auto-provision and effortlessly run the job, eliminating complex environment setup and management. Check for more details at https://https://docs.tensoropera.ai/launch.
Enterprise service: If you are not satisfied with the performance of your LLM Agent, we can provide you with guidance in LLM fine-tuning, RAG optimization, and prompt engineering contact us .
5. Compute
5.1 Serverless Secure GPU Cloud (On-demand)
TensorOpera provides your ML team with a fully managed GPU cluster with the pre-installed TensorOpera Platform. TensorOpera Platform provides useful features to accelerate your AI development, including GPU job scheduling, training, deployment, experimental tracking, and monitoring.
5.2 Dedicated Secure GPU Cloud
TensorOpera provides your ML team with a fully managed GPU cluster with the pre-installed TensorOpera} Platform. TensorOpera} Platform provides useful features to accelerate your AI development, including GPU job scheduling, training, deployment, experimental tracking, and monitoring.
Note: Approximate pricing based on available GPUs in TensorOpera Secure Cloud
Enterprise service: If you need help with complex custom deployment (multiple models, cross-server workflow, distributed serving in multiple clouds, etc.) or throughput/latency optimization, don't hesitate to contact us .
6. Monetization Service
6.1 Monetize Your Model
We appreciate the model creator's effort, whether the model is open-sourced or closed-sourced. TensorOpera can provide model owners a payment and serving platform to monetize the model. Serve your model, turn it into a model API, and bind your credit, you will receive earnings when users call and pay for your APIs.
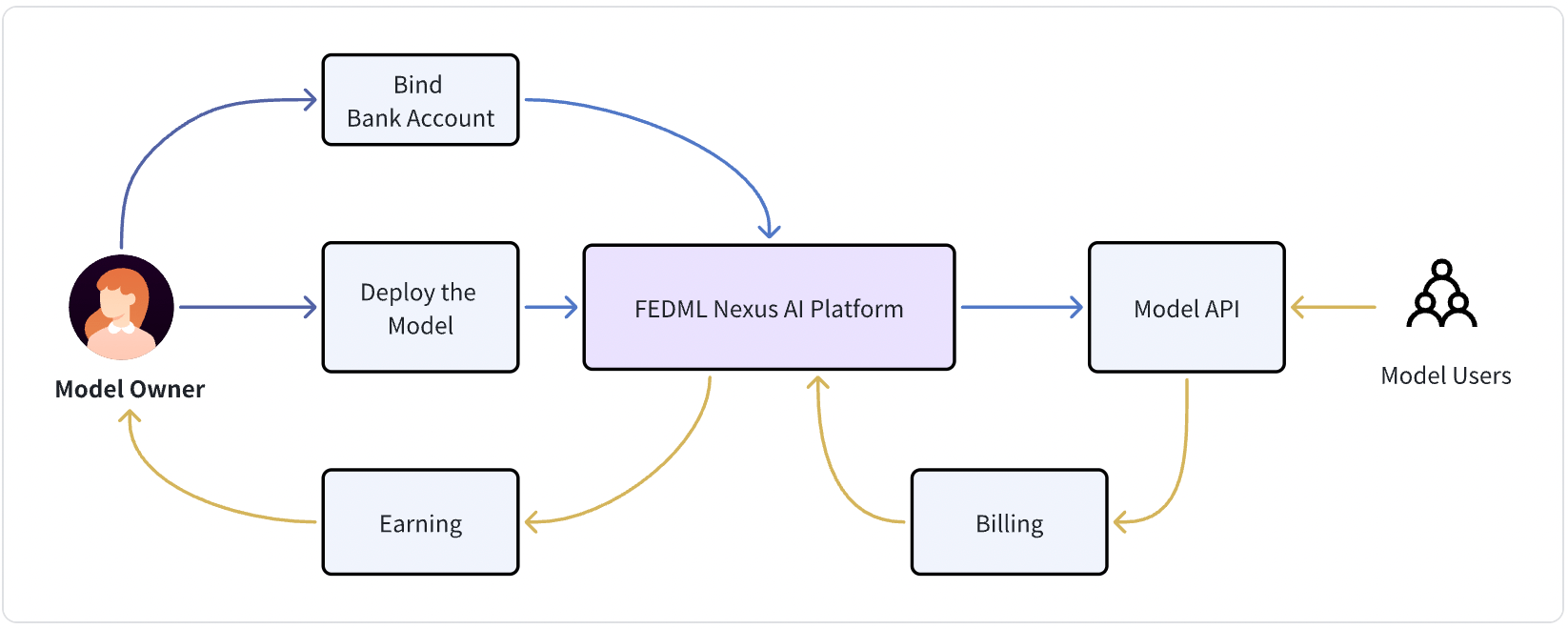
Enterprise service: If you want to customize the revenue-sharing mechanism or the endpoint API and related landing page for your own customers, please contact us .
6.2 Share Your GPUs and Earn
Share your GPU(s) with our GPU marketplace and earn money to pay back your investment. More details are at https://docs.tensoropera.ai/launch/share-and-earn.
- Cloud GPU Provider
- Edge GPU Provider
- Individual GPU Provider
Enterprise service: If you want to integrate a large number of GPUs into TensorOpera Cloud backend systems to allow AI developers to run TensorOpera Launch serverless jobs, please contact us .