TensorOpera and Qualcomm Technologies Join Forces to Provide the World's Most Cost-Effective AI Inference for LLMs and Generative AI on TensorOpera AI Platform
For Enterprise AI
Do you need enterprise-level control, ownership and scalability as follows?
- Custom rate limits
- Autoscaling
- Deploy your fine-tuned custom models
- Compound AI and workflow management
- Custom monitoring, altering, and report
- Platform on-premise deployment
- Security, and privacy
- Dedicated support
Please fill in the form and let us know your requirements. Our team from TensorOpera and Qualcomm will reach out shortly to discuss how we serve your business better.
For Developers, Startups, SMBs
Early Access to Public Serverless APIs
Developers can apply for early access serverless APIs on Llama3-70B, Llama3-8B, and SDXL. Please contact us if you need other open-source model support.



To apply for early access, please register your account at https://tensoropera.ai and then fill in the form about your use cases and API Key (see screenshot below). We will then add your API Key to the white list.
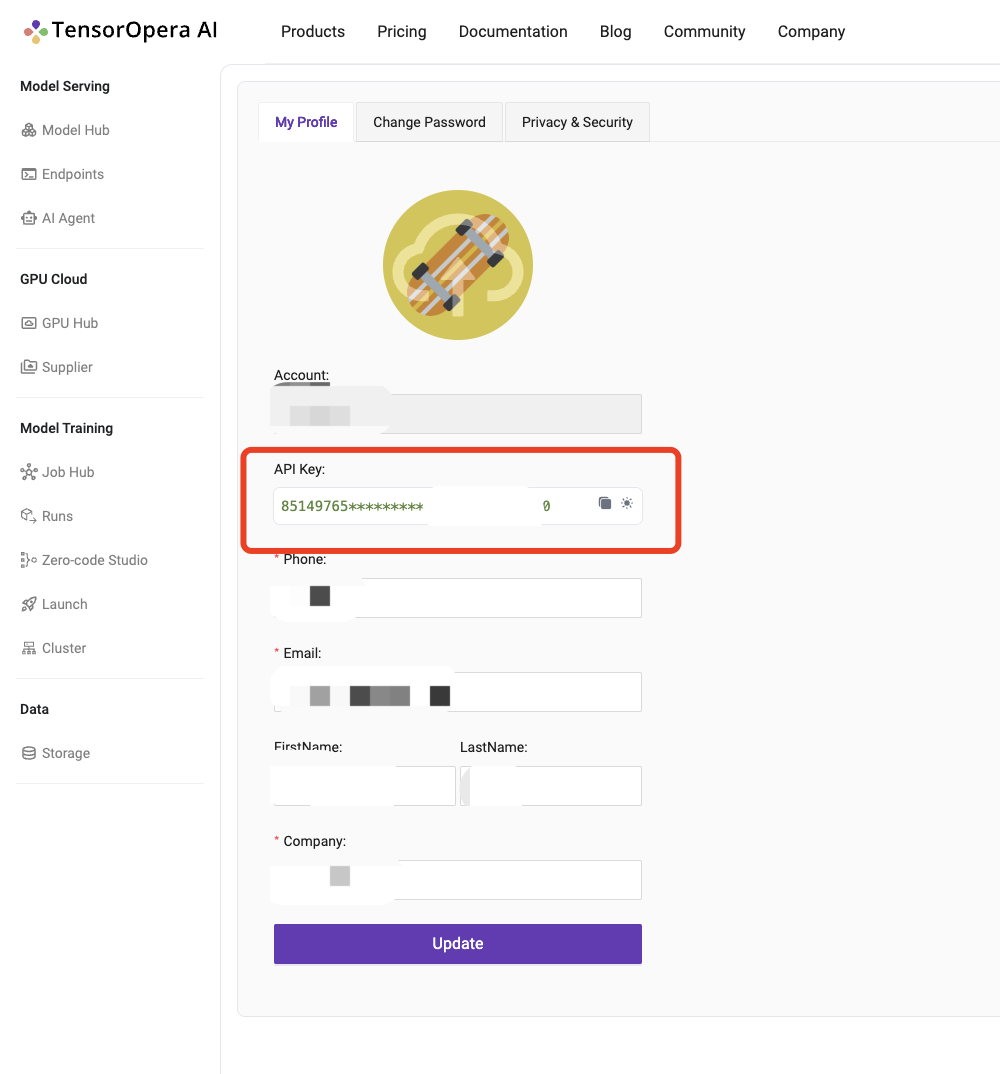
For LLMs, our serverless APIs are fully compatible with OpenAI's client APIs. You just need to change the API_Key and URL as follows:
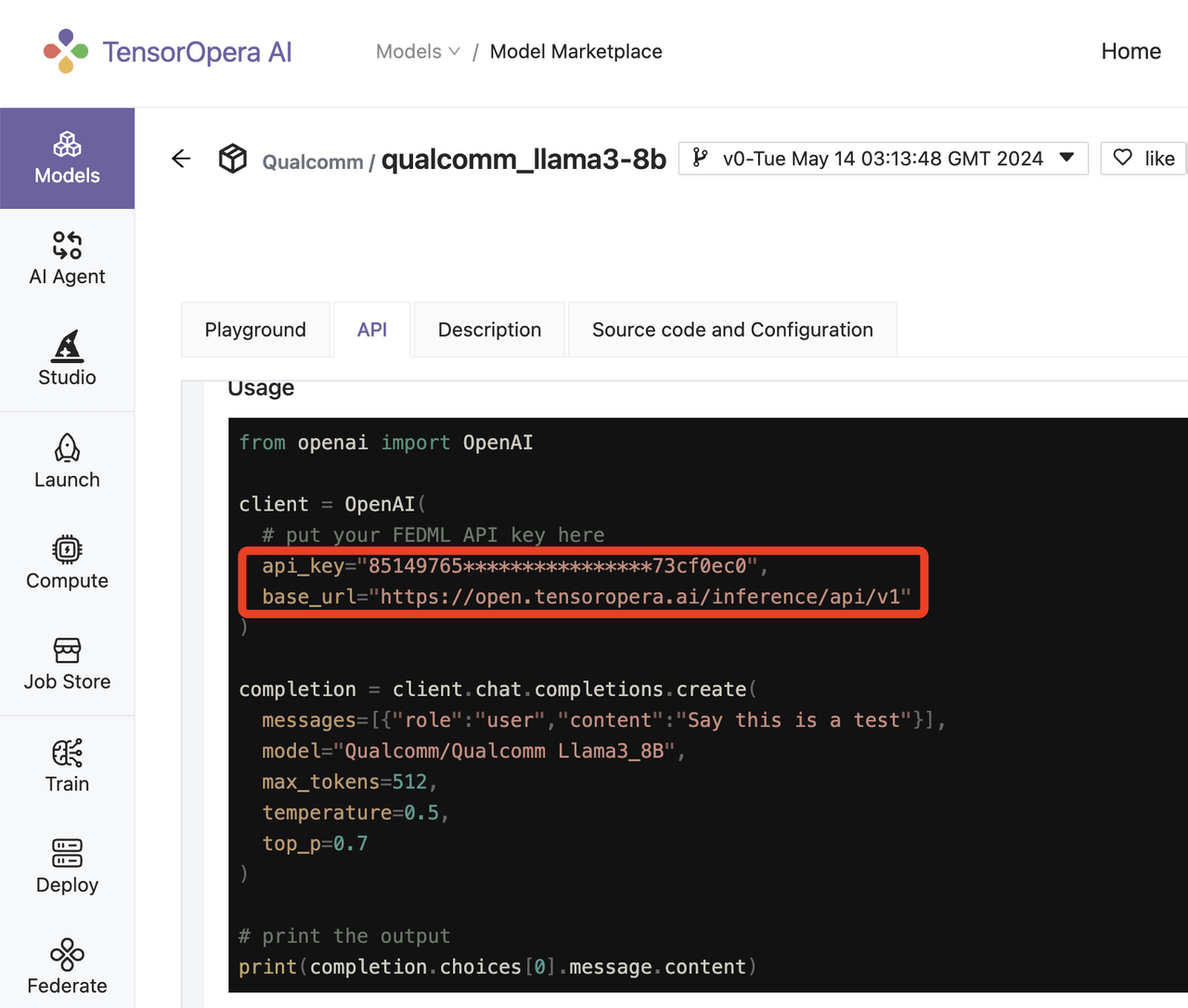
For technical support and feature requests, please join our Slack or Discord community.
Self-service to Public Serverless APIs
After the early-access phase, we will allow any developers access the APIs by self-service. You just need to register at https://tensoropera.ai, go to the "Models" Tab, find Qualcomm related models, and select the "API" Tab, you will see the guidance of the API usage.
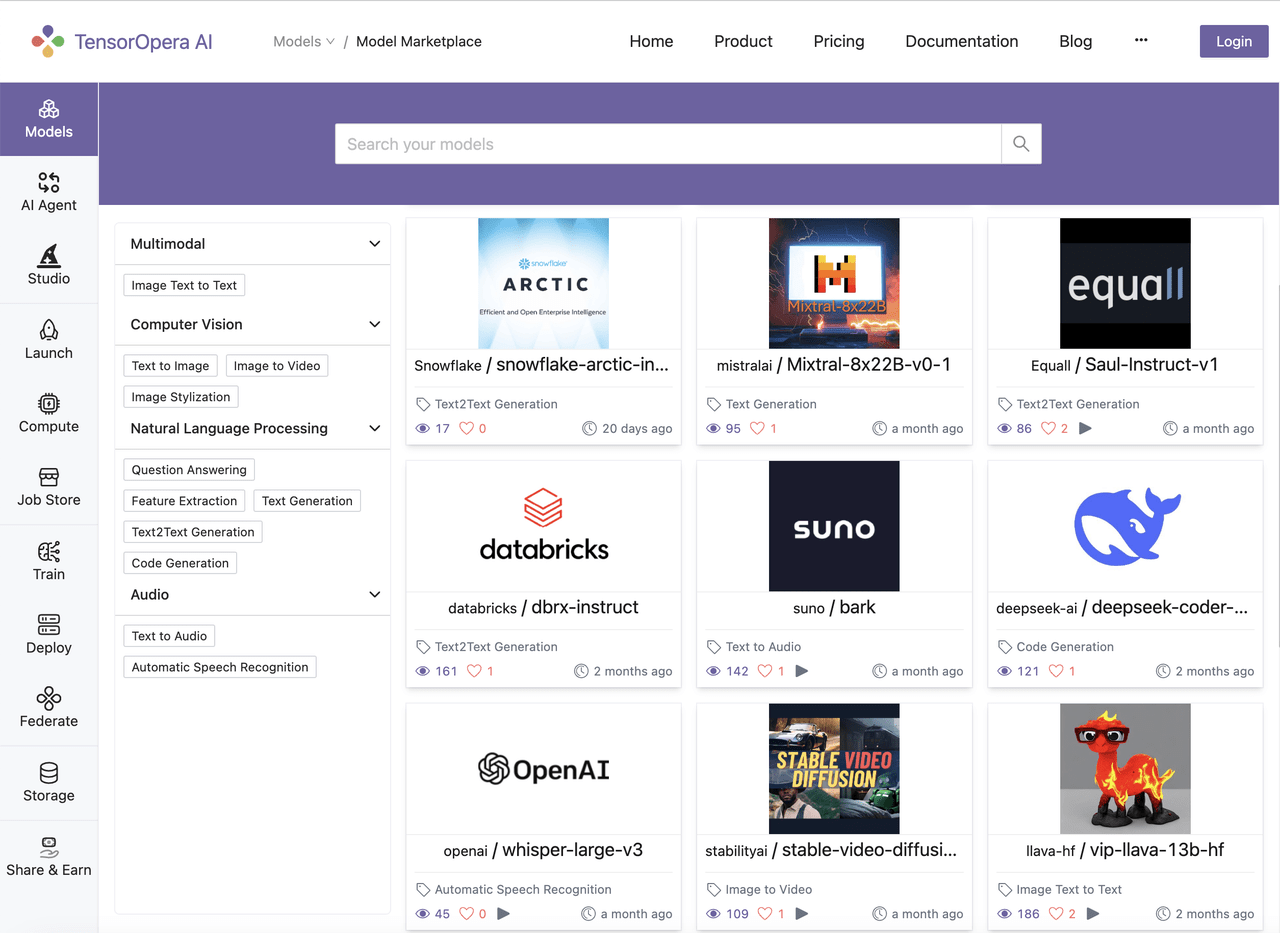
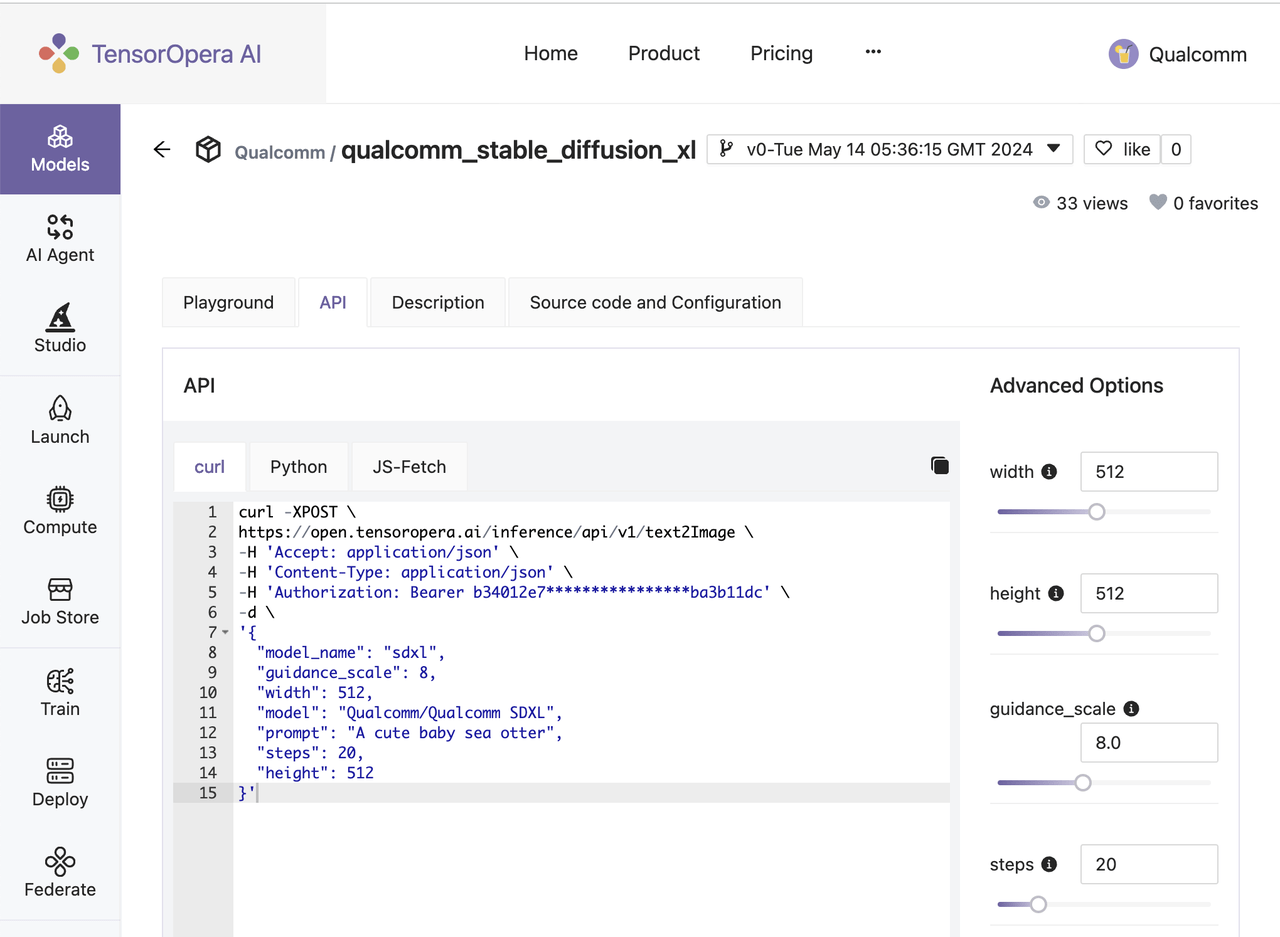
Price
| Qualcomm AI 100 | $0.40/GPU/hour |
| Llama 3 70B (8K Context Length) | $0.45/$0.45(per 1M Tokens, input/output) |
| Llama 3 8B (8K Context Length) | $0.05/$0.05(per 1M Tokens, input/output) |
| SDXL | $0.00005(per Step / 512 x 512 Image) |
| SDXL | $0.0001(per Step / 1024 x 1024 Image) |
Note: if you need more model support, please let us know by Slack, Discord or Concat .
About Scalable Model Serving Platform at TensorOpera AI
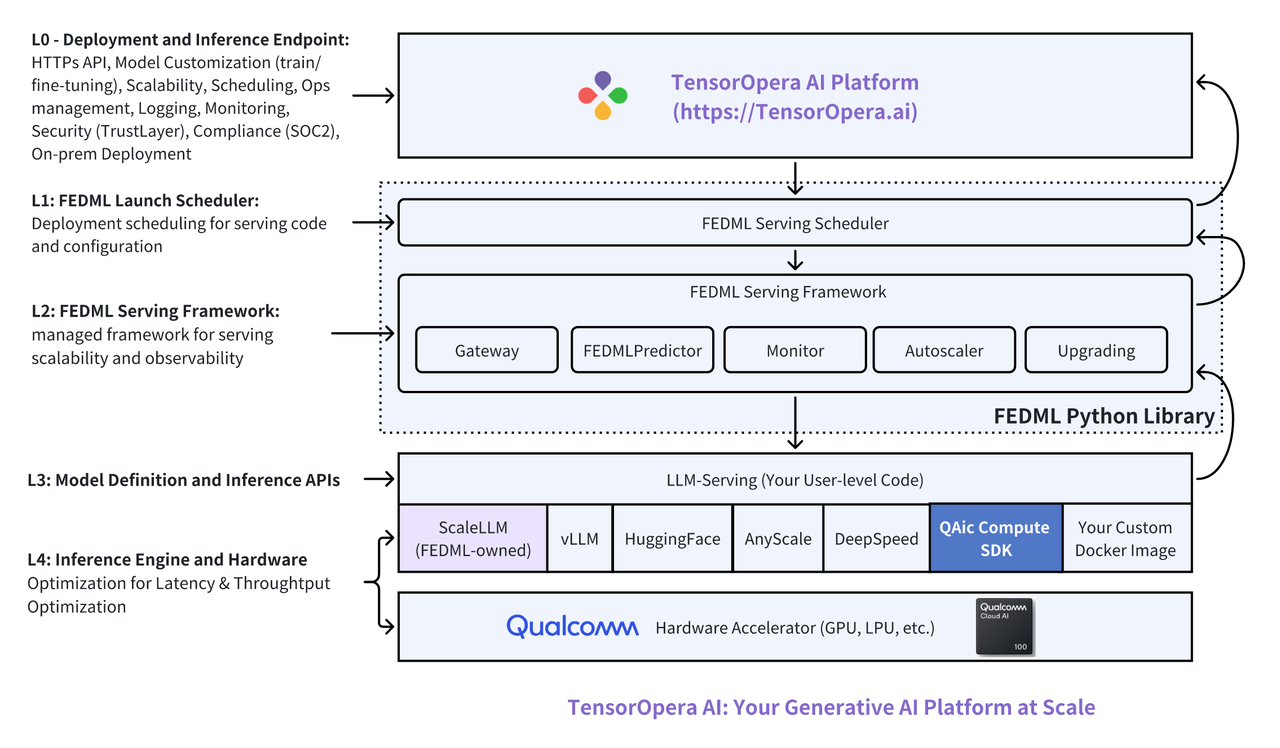
The figure above shows TensorOpera AI's perspective of model inference service. It's divided into a 5-layer architecture:
- Layer 0 (L0) - Deployment and Inference Endpoint. This layer enables HTTPs API, model customization (train/fine-tuning), scalability, scheduling, ops management, logging, monitoring, security (e.g., trust layer for LLM), compliance (SOC2), and on-prem deployment.
- Layer 1 (L1) - TensorOpera Launch Scheduler. It collaborates with the L0 MLOps platform to handle deployment workflow on GPU devices for running serving code and configuration.
- Layer 2 (L2) - TensorOpera Serving Framework. It's a managed framework for serving scalability and observability. It will load the serving engine and user-level serving code.
- Layer 3 (L3) - TensorOpera Definition and Inference APIs. Developers can define the model architecture, the inference engine to run the model, and the related schema of the model inference APIs.
- Layer 4 (L4): Inference Engine and Hardware. This is the layer many machine learning system researchers and hardware accelerator companies work to optimize the inference latency & throughput. At TensorOpera, we've developed our in-house inference library ScaleLLM (https://scalellm.ai )
For more details, please read our blog at: https://blog.tensoropera.ai/scalable-model-deployment-and-serving-platform-at-fedml-nexus-ai/